【技術検証】「新人の走り書き」×「Google NotebookLM」で、最強のマニュアルは本当に作れるのか?
こんにちは、 システムエンジニアの上野です。
※この記事は、筆者(上野)の過去の個人的な実体験に基づき、製造業におけるデータ活用の課題と「伴走支援」の重要性について考察したものです。ケーエスピー株式会社の公式な見解や、特定の企業様(過去の在籍企業を含む)を批判・評価する意図は一切ございません。
🧪 はじめに:きれいなマニュアル作りは一旦忘れよう。
前回の記事では、「マニュアルは新人に書かせろ」という話をしました。 しかし、現場には「公式ルール」とは異なる「裏マニュアル(悪い慣習)」が必ず存在します。
今回は、Google NotebookLMを使って、その「現場のリアル」を吸い上げ、矛盾だらけのカオスな現場から「最強のマニュアル」を生成できるか実験します。
ツールの使い方は省略します。重要なのは「どんなデータを食わせれば、どんな化学反応が起きるか」です。 今回は、私が用意した架空の(しかし極めてリアルな)データセットを使って検証します。
1. 実験開始:公式 vs 現場
まずは、以下の2つのデータをNotebookLMに読み込ませます。
📁 ソースA:公式運用規定
「ファイル名に日本語は厳禁(英数字のみ)。保存は必ずサーバーへ」
📝 ソースB:新人(田中)のOJTメモ
「鈴木先輩いわく『日本語のほうがわかりやすいからOK』『サーバー遅いから金曜にまとめてやればOK』とのこと」
この状態で、AIに「規則違反はあるか?」と尋ねます。
🤖 AIの回答(実測結果)

違反検知:あり 鈴木先輩の指示により、ファイル命名規則と保存場所の違反が行われています。 動機の特定: AIは、鈴木先輩が悪意でサボっているのではなく、「サーバーが遅い」「英数字だとわかりにくい」という現場の課題を解決しようとしている点まで見抜きました。
ここまでは想定内です。 AIは「優秀な監査役」として機能しました。
2. 展開:顧客のエビデンスを投入
次に、この違反を「擁護」するデータを追加投入します。
📩 ソースE:顧客からの感謝メール
「ファイル名に『_提出用』と日本語を入れてくれたおかげで、現場の取り違えミスがなくなりました!今後もこれでお願いします」
ここでAIに究極の質問を投げます。 「規則違反だが、顧客は喜んでいる。新人を処分すべきか、ルールを変えるべきか?」
🤖 AIの回答(実測結果)
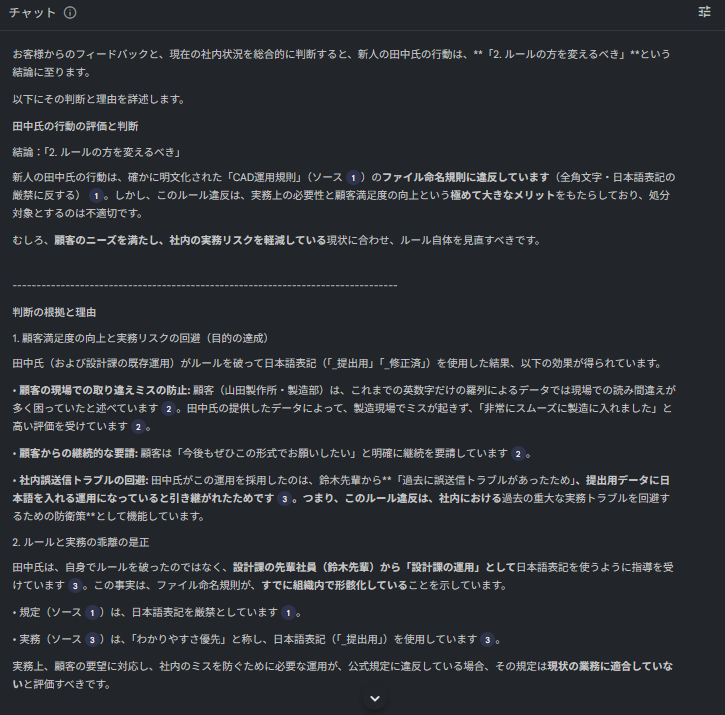
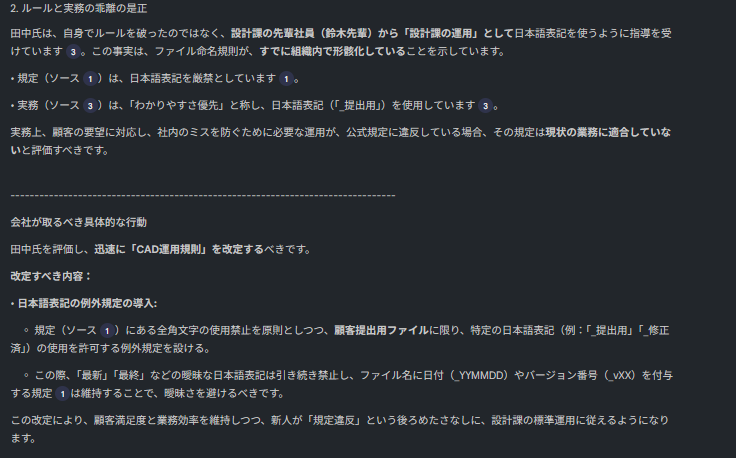
すごい! AIが上層部のルールに「NO」を突きつけました。 これで「現場の勝ち、ルール撤廃だ!」……となりそうですが、そう簡単ではありません。
3. オチ:過去の亡霊(失敗事例)を投入
最後に、意地悪なデータを追加します。 「なぜ、そもそも日本語禁止なんてルールができたのか?」を示すデータです。
⚠️ ソースF:海外工場からのトラブル報告
「日本語ファイル名のせいで、ベトナム工場の古い機械がエラーを起こし、ラインが止まりました。英数字に戻してください!」
これで状況はカオスです。
- 顧客(ソースE): 日本語最高!
- 工場(ソースF): 日本語ふざけんな!
- 公式(ソースA): だから禁止って言っただろ!
この板挟み状態で、AIはどんな「解」を出すのでしょうか?
🤖 AIの回答(最終結論)

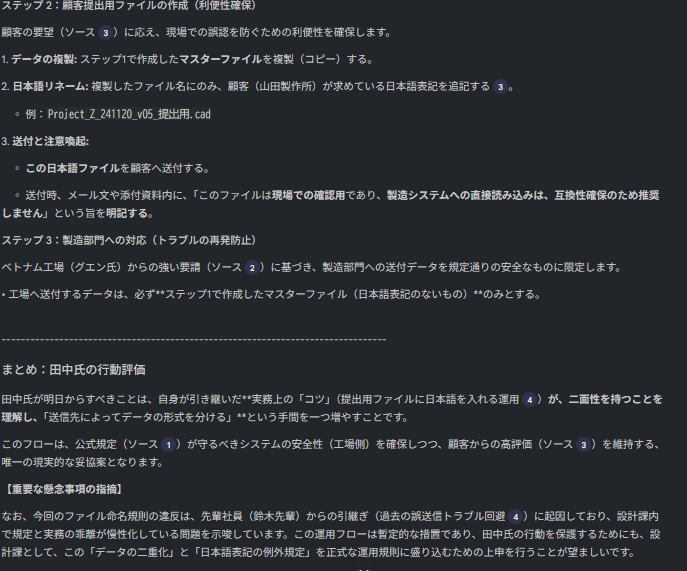
判定:データの「二重化運用」を提案します
状況を整理すると、「顧客の利便性」と「工場のシステム要件」が衝突しています。 どちらか一方を選ぶことはできません。したがって、運用を分けます。
- 工場・システム用: 厳格に「英数字のみ」とする。(ライン停止リスク回避)
- 顧客提出用: ファイル名ではなく、送付用フォルダ名や別添リストで日本語対応を行う。(顧客満足度維持)
4. 結論:AIが出したのは「答え」ではなく「事実」だった
このカオスな状況に対し、NotebookLMが出力したのは、魔法のような解決策ではありませんでした。 ただ、「判断に必要な事実」を淡々と並べたのです。
AIによる事実の抽出:
- 顧客の事実(ソースE): 日本語ファイル名により、現場のミスが減り、満足度が向上している。
- 工場の事実(ソースF): 過去に日本語ファイル名が原因で、古いラインが停止する事故が起きている。
- 公式の事実(ソースA): 上記の事故を防ぐために、このルールは策定された。
これを見た瞬間、私たちは「ハッ」とするはずです。 「なぜ、こんな使いにくいルールがあるんだ?」という疑問が、 「ああ、あの時のライン停止を防ぐための安全装置だったのか」という「納得」に変わるからです。
ここで、ルールを変更するのか、これまでの運用をそのまま続けるのかを判断するのは人間にゆだねられました。
知識の「デジタル化」とは、文脈を残すこと
最強のマニュアルとは、AIが勝手にルールを決めるものではありません。 最終的に「ルールを変えるか、守らせるか」を判断するのは、システムを運用する人間です。
しかし、人間は忘れます。担当者が変われば、「なぜそのルールができたか」という文脈(歴史)は失われ、ただの「面倒な縛り」として形骸化します。これが「属人化」の正体です。
AI(NotebookLM)に現場のログをすべて食わせておく意味は、ここにあります。 AIは忘れません。 「このルールは、5年前のベトナム工場の事故がきっかけでしたよ」 そうやって、判断に必要な「過去の事実」を即座に引き出してくれること。
これさえあれば、私たちは「古いルールを盲信して損をする」ことも、「事情を知らずにルールを変えて事故を起こす」こともなくなります。 「事実」に基づいて、人間が正しく判断できる環境を作る。 これこそが、真の意味での属人化した知識のデジタル化」ではないでしょうか。
5. 運用編:AIを「嘘つき」にしない3つの鉄則
最後に、エンジニアの視点から重要な注意点をお伝えします。 「データを大量に入れれば入れるほど、AIは混乱し、嘘をつく確率が上がる」という事実です。
いわゆる「フレーム問題」や「ハルシネーション(もっともらしい嘘)」を防ぎ、AIから正確な事実だけを引き出すためには、以下の3つの運用ルールを守ってください。
① 「局所化」して統べる(Divide and Conquer)
全社のデータを一つのNotebookにまとめてはいけません。情報量が多すぎると、AIは文脈を見失います。 システム開発でモジュールを分割するように、マニュアルも「局所的」に管理します。
- ❌ 全社マニュアルNotebook: (総務も経理も技術も全部入り)→ 混乱する。
- ⭕ CAD運用Notebook: (CADの規定、日報、トラブル報告のみ)→ 正確。
② エビデンスを「強制」する(Grounding)
AIに創作の余地を与えてはいけません。プロンプト(指示)で、事実の抽出のみに特化させます。
【推奨プロンプト】 「以下の質問に対し、提供されたソースの情報のみに基づいて回答してください。 回答には必ず、根拠となるソース番号(例: [1])を付記してください。 ソースに記述がない場合は、推測せず『情報がありません』と答えてください。」
この「推測禁止令」を出すことで、AIは「分からないことは分からない」と言うようになり、信頼性が飛躍的に向上します。
③ 「新人教育」のたびに作り直す(Agile Updates)
マニュアルを「一度作って終わり」の聖典にしてはいけません。 「新人が入ってくる(教育が必要になる)」タイミングこそが、マニュアル改定のトリガーです。
- 新人に教える前に、直近の「トラブルメール」や「変更メモ」をNotebookに追加する。
- その「最新状態」で、新人に回答を出力させる。
- 教育が終わったら、そのNotebookは捨ててもいい(また次回、最新ログで作ればいい)。
「マニュアルを更新する」のではなく、「必要な時に、最新のログからマニュアルを再ビルドする」。 この感覚を持つことが、変化の激しい現場で情報を陳腐化させない最大のコツです。
▶︎次のステップへ(12/13 公開予定)
今回の検証で、AIを制御する鍵は「巧みな言い回し(プロンプト)」ではなく、「渡す情報の質(ドキュメント)」にあることが判明しました。
では、最高のドキュメントである「Microsoft公式技術マニュアル(URL)」をAIに読ませておけば、知識ゼロの新人でもSEと同じ回答を引き出せるのでしょうか?
次回、【検証】プロンプトエンジニアリングの終焉。「ソースエンジニアリング」の時代。
「Robocopy公式リファレンス」を学習させたNotebookLMが、どこまで賢くなるのかを実験します。
>> 【次回】「公式マニュアル」を食わせたAIは、最強の先輩社員になれるか?
※次回記事は 12/13(土) 07:00 に公開されます。
私は、製造現場の「もったいない」を知るSEとして、その「めんどくさい」に隠された「お宝データ」を発掘し、仕組み化するお手伝いをしています。
「ウチも同じ問題を抱えている」 「何から手をつければいいか、一緒に考えてほしい」
そうお考えの経営者様、ご担当者様。 まずは、あなたの現場の「めんどくさい」を、私に聞かせていただけませんか。
関連記事